架构师-第五阶段:数据库架构
1、读性能,究竟如何提升?
- 库表结构,索引结构,设计依据
- 依据“业务模式”,设计库表结构
- 依据“访问模式”,设计索引结构
- 谁在 where 后面,就在谁上面加索引
- 索引的建立要避免性能降低,主从同步的,在主库不建立索引,在从库建立索引,如下图:
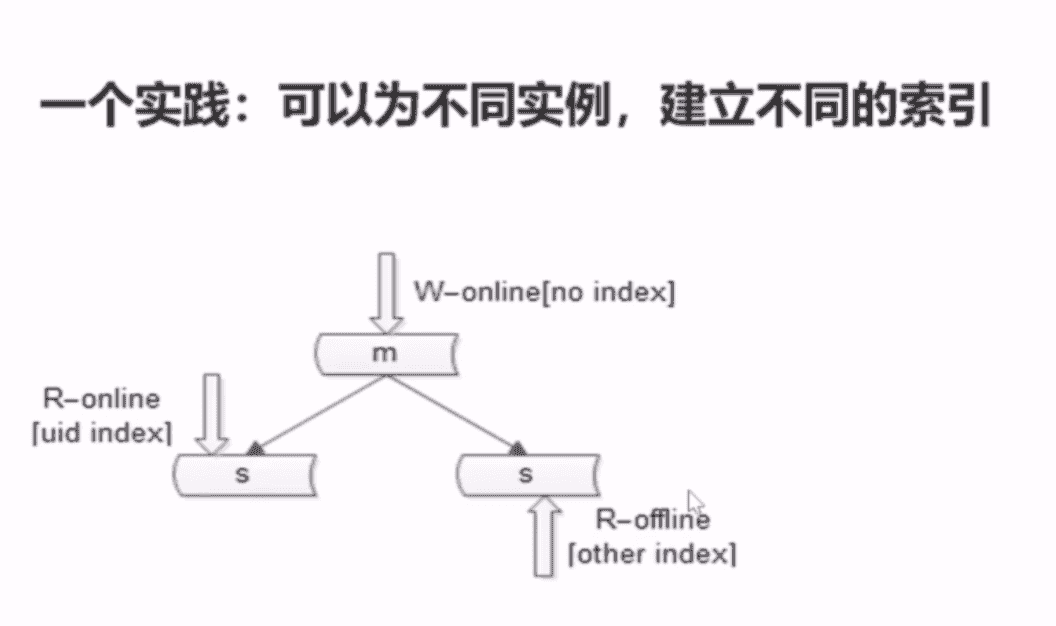
增加从库(主从同步)
主从分组架构,提高的是读性能,没有解决数据水平扩容和写性能增加缓存,增加了服务层如下图:
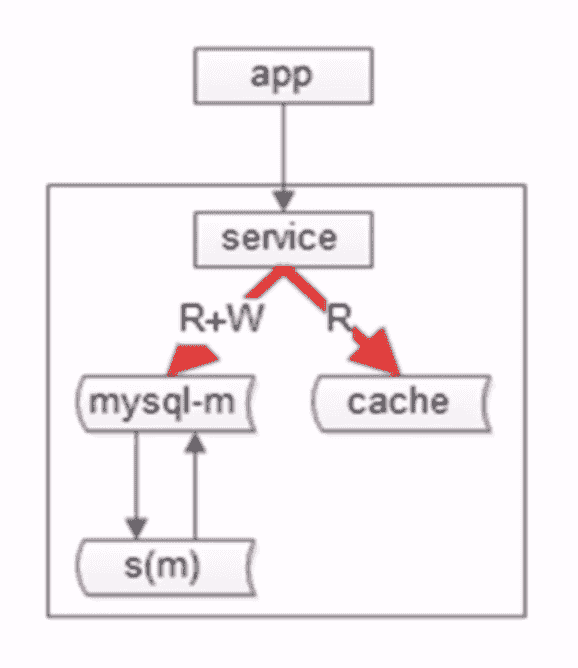
缓存是万金油,不管是否有微服务分层,都可以使用缓存 读的时候,先取出数据,更新缓存;写的时候,先淘汰缓存,后写入
2、垂直拆分,到底怎么实施?
- 垂直拆分
- user(单库)-> user_base user_ext1 user_ext2 … user_extn
- 常用的,长度短属性的放在主表里
- 不常用的,字段较长的属性放在扩展表里
- 如果熟悉很多,可以有多个扩展表
- 缓冲池有具体的大小,所以会影响索引查询的性能,如下图:

水平切分
一个表按照 hash 规则分成多个表,例如取用户 id 的模(uid%2)
user(单库) -> user0 user1 … usern
- 高可用
- 冗余+故障自动转移来实现
- 数据库冗余,会引发一致性问题
3、主从一致性,究竟如何解决?
- 业务能够接受,就可以忽略不计
- 强制读主,
主从同步分组架构,选择性读主
用一个 key放在缓存里来做标识 在一秒内有主库操作,当读的时候,先去找这个 key,如果 key 存在,那就读主库,如果不存在,就读从库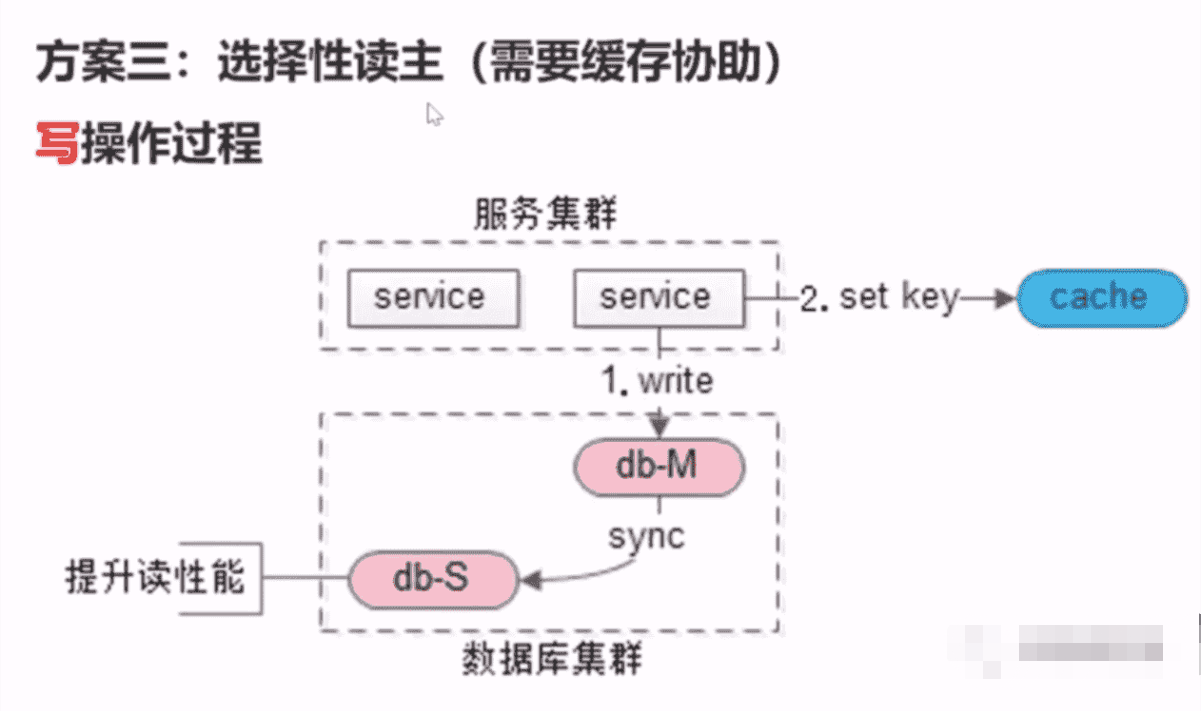
- 主主同步结构
- 两个数据库,不同初始值,相同递增步长
- 在数据库上层应用程序控制自增 id 的生成,例如:分布式 id 生成算法、雪花算法
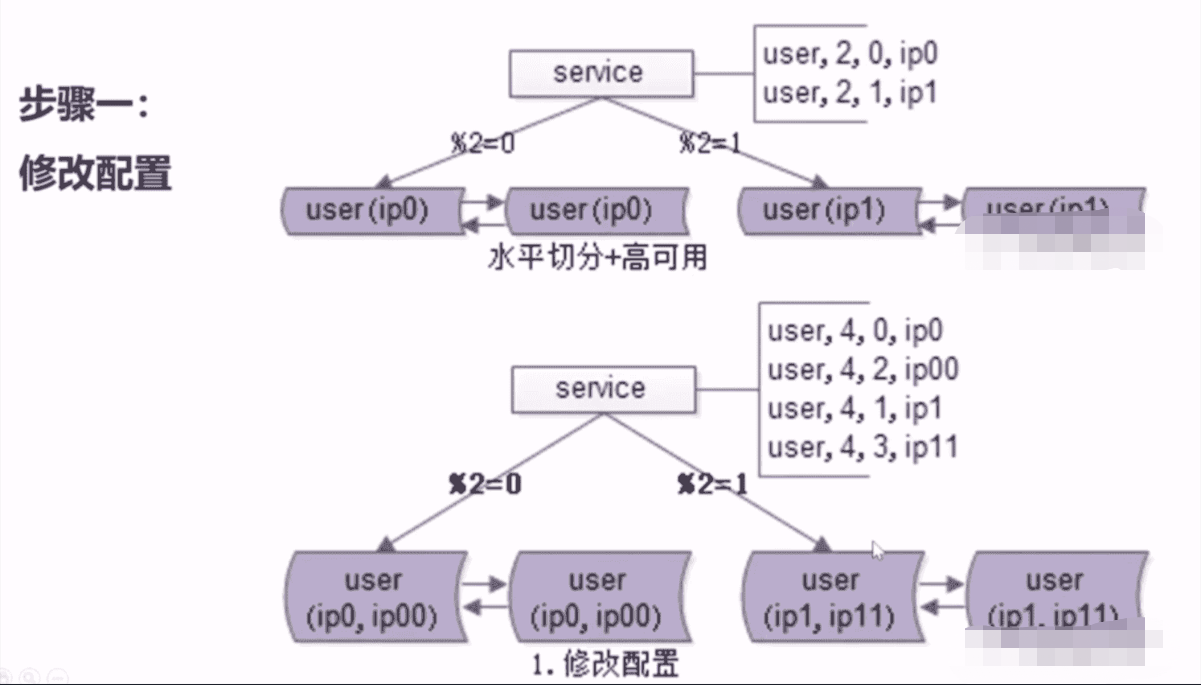
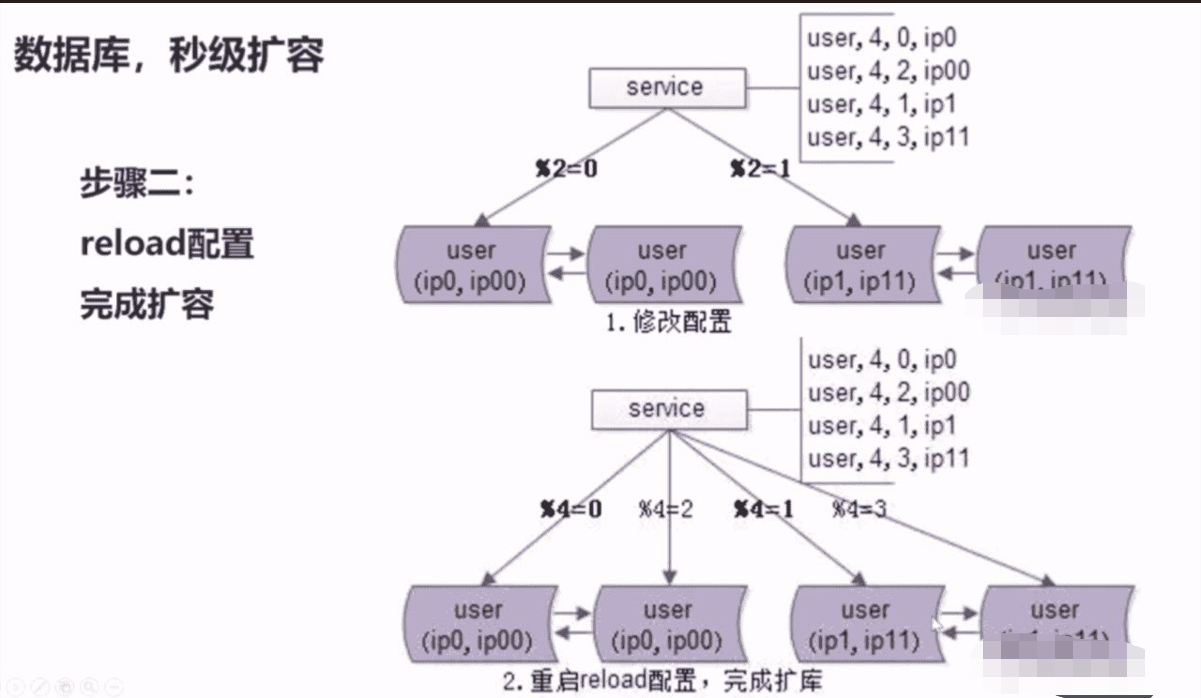
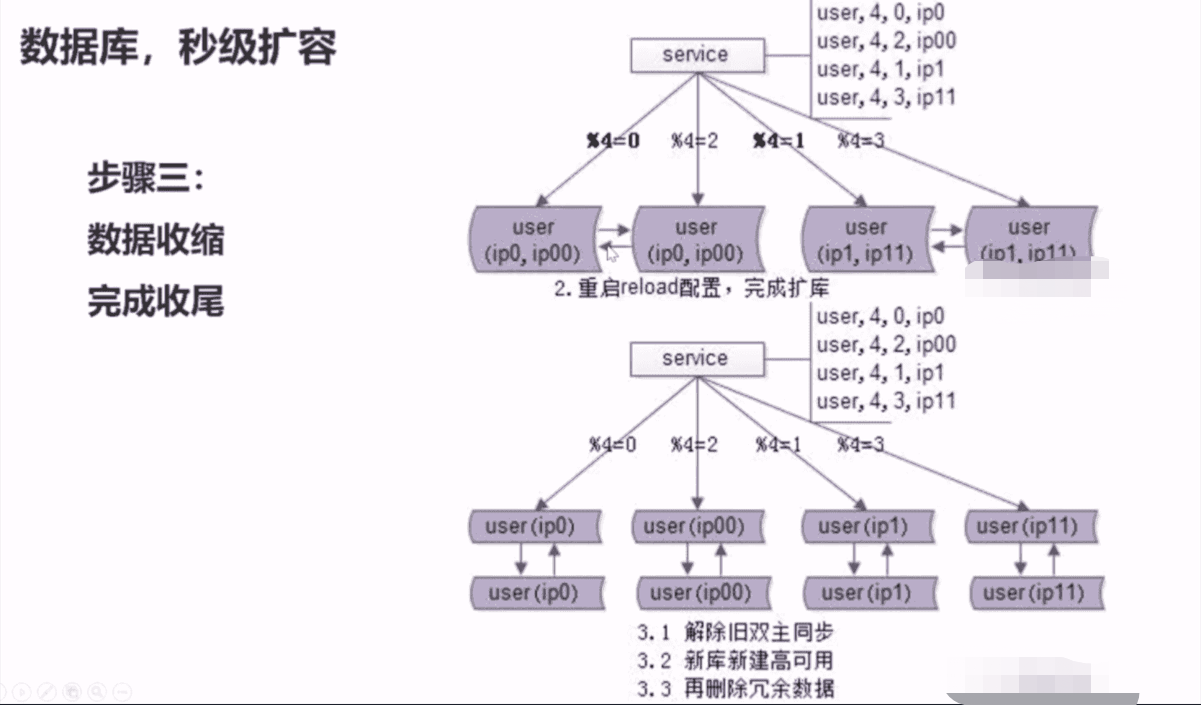
4、水平拆分,怎么做到无限容量?
- 哪些情况需要扩展?
- 底层表结构变更
- 水平扩展,分库个数变化
- 扩展方案
- 停服扩展,必须在规定的时间内解决
- 在线表结构变更(online schema change ),
https://blog.csdn.net/shiyu1157758655/article/details/84854513
- 追日志
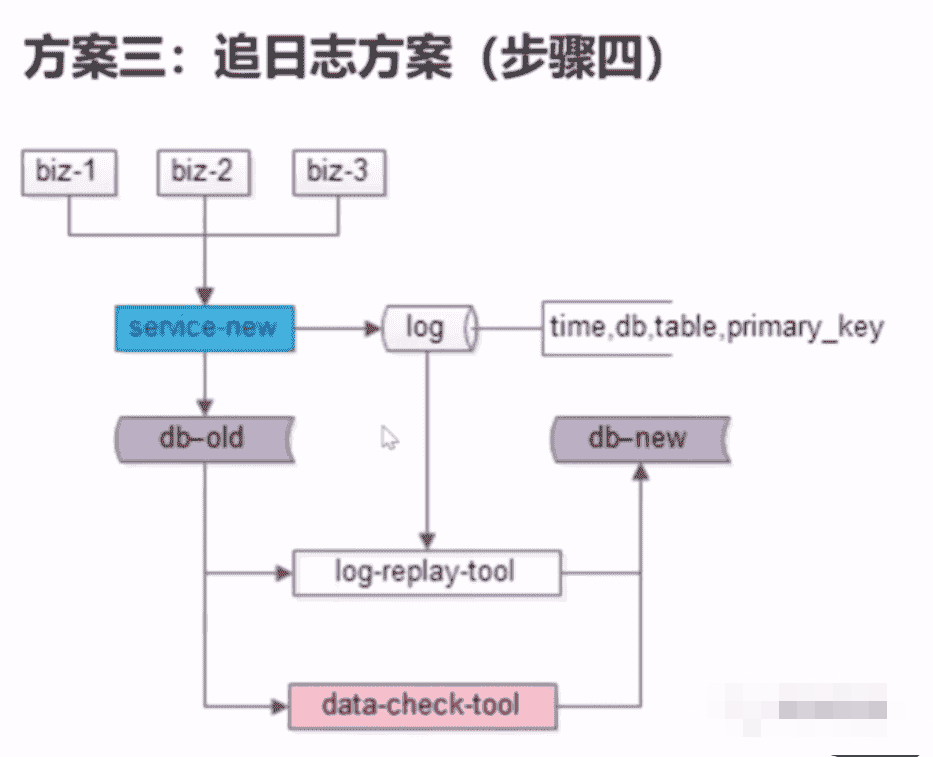
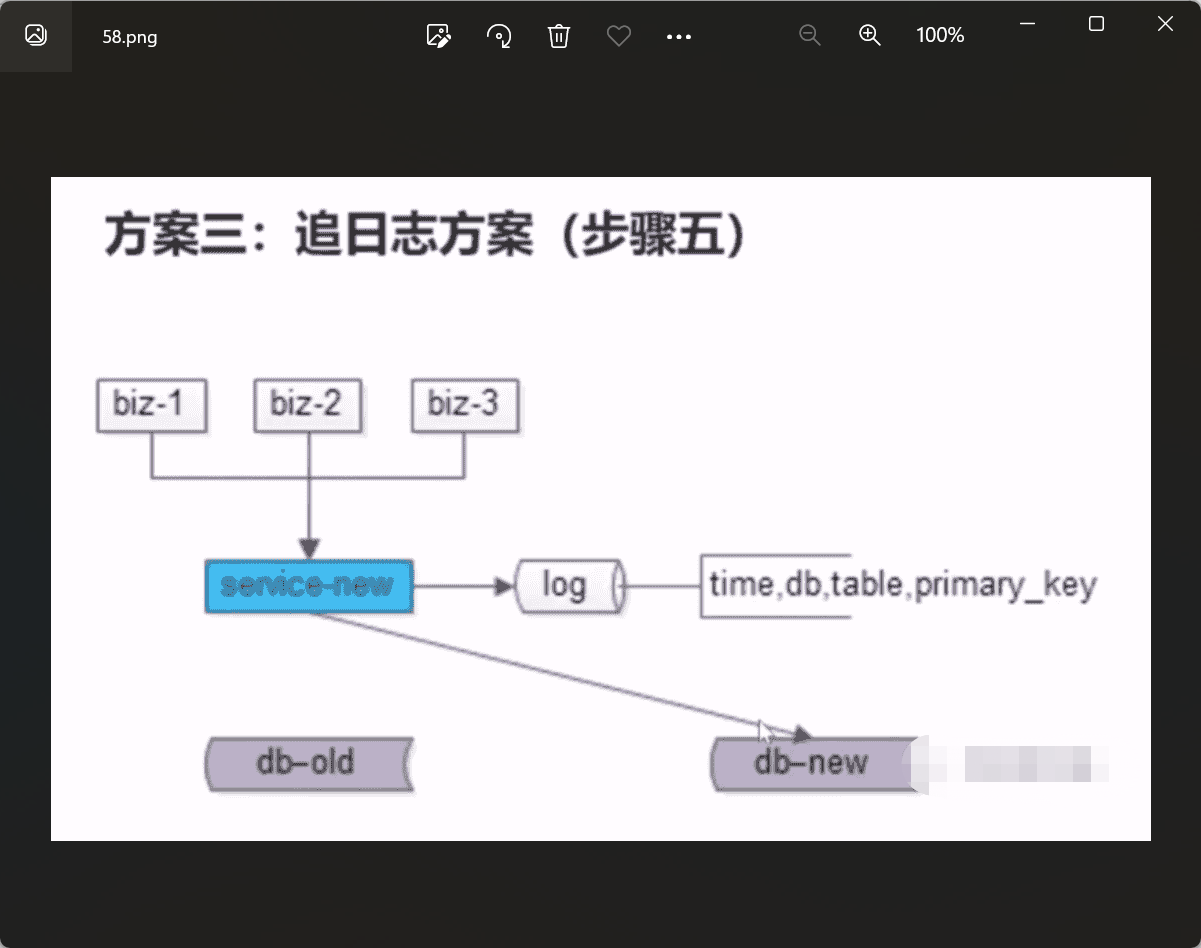
总结
5、扩展性,如何平滑迁移与扩容?
- 扩展方案四
- 双写方案